Observability

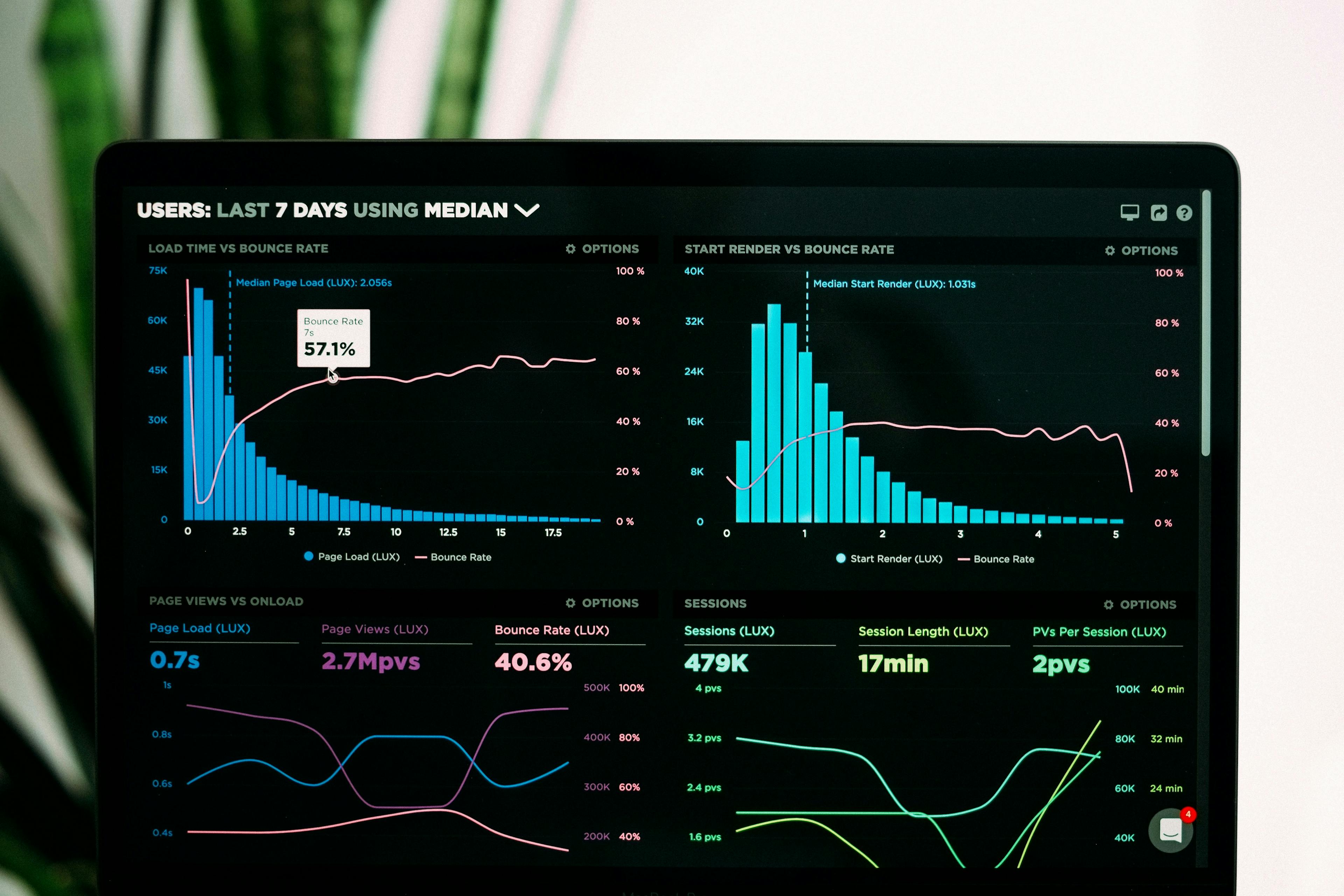
Observability는 로그, 메트릭, 트레이스 등의 output으로부터 시스템의 내부 상태를 유추할 수 있는 역량을 말한다.
애플리케이션은 다양한 이유로 실패할 수 있다. CPU 사용량이 급증하거나 메모리 누수가 발생해서 서비스가 중단되었을 수도 있고, 개발자의 실수로 인한 버그가 앱을 비정상 종료시키고 있을 수도 있다. Observability는 시스템의 다양한 데이터를 수집해 우리가 한 눈에 그 시스템의 현 상태를 점검할 수 있게 하는 개념이다. 이를 위해 로그, 메트릭, 트레이스 등을 수집하고 시각화한다.
로그(log)
로그는 텍스트 형태로 된 이벤트에 대한 기록이다. 어떤 이벤트가 발생하면 그 이벤트에 대한 텍스트 기록이 남는다. 로그는 개발자에 의해 의도적으로 추가될 수도 있고, 시스템 레벨에서 특정 이벤트별로 자동으로 생성할 수도 있다. CPU 사용량과 같은 수치만 알고 있다면, 사실 앱의 어떤 부분이 문제가 되어 CPU 사용량이 급증했는지 결코 이해할 수 없다. 하지만, CPU 사용량이 급증한 시간대에 특정 이벤트에 대한 로그가 급증했다면, 그 이벤트가 CPU 사용량에 영향을 미친 것이라고 유추해볼 수 있게 된다. 따라서 로그는 매우 갚진 데이터라 말할 수 있다.
메트릭(metric)
메트릭은 숫자형태로 시스템의 상태를 나타내는 값이다. 앞서 주기적으로 등장한 CPU 사용량, 메모리 사용량 같은 것이 메트릭에 해당한다. 메트릭은 실시간 모니터링을 위해 사용되며, 큰 틀에서의 시스템의 health와 퍼포먼스에 대한 정보를 제공한다.
트레이스(trace)
트레이스(Trace)는 분산 시스템에서 요청이 시스템의 다양한 컴포넌트를 거치는 과정을 상세하게 추적하는 방법이다. 각 단계나 컴포넌트를 지나갈 때마다 해당 요청에 대한 정보를 기록하여, 전체 요청 경로와 각 컴포넌트에서의 처리 시간을 파악할 수 있게 한다. 이를 통해 시스템의 성능 병목 현상이나 지연, 실패의 원인 등을 정밀하게 분석할 수 있다.
트레이스는 특히 분산시스템에서 중요한데, 하나의 요청이 여러 컴포넌트를 거치는 구조이기 때문에 트레이스를 활용하면 개별 요청의 흐름을 쉽게 파악할 수 있다.
Prometheus와 Grafana에 대해
Prometheus
Prometheus는 오픈 소스 모니터링 시스템으로, 시스템이나 서비스에서 발생하는 메트릭(성능 지표)을 수집하고 저장한다. 이를 통해 실시간으로 시스템의 상태를 모니터링하고, 문제가 발생했을 때 경고를 발생시키는 등의 기능을 제공한다. Prometheus는 특히 시계열 데이터 관리에 최적화되어 있으며, 강력한 쿼리 언어인 PromQL을 통해 데이터를 쉽게 조회하고 분석할 수 있다.
Grafana
Grafana는 데이터 시각화 및 분석을 위한 오픈 소스 플랫폼이다. 다양한 데이터 소스를 연결하여 대시보드를 만들 수 있으며, 이를 통해 데이터를 그래프, 차트, 알림 등의 형태로 쉽게 보여준다. Grafana는 Prometheus와 자주 함께 사용되어, Prometheus에서 수집한 메트릭 데이터를 시각적으로 표현하고, 사용자가 시스템의 상태를 한눈에 파악할 수 있도록 돕는다.
간단한 앱에 모니터링 환경 구축하기
docker-compose로 Go App server, Prometheus, Grafana를 연동해 모니터링 환경구성해본다.
Go-echo 앱
아주 간단한 앱을 만들어본다.
route는 총 세개다
- /metric: prometheus에서 메트릭을 수집하기 위한 route
- / : hello world를 전송해준다
- /slow: 1초 지연 후 “ok”가 반환된다. request 지연에 대한 대시보드를 만들기 위해 인위적으로 구성했다.
package main import ( "net/http" "time" "github.com/labstack/echo-contrib/echoprometheus" "github.com/labstack/echo/v4" ) func main() { e := echo.New() // echo prometheus e.Use(echoprometheus.NewMiddleware("app")) e.GET("/metrics", echoprometheus.NewHandler()) e.GET("/", func(c echo.Context) error { return c.String(http.StatusOK, "Hello, World!") }) e.GET("/slow", func(c echo.Context) error { time.Sleep(1 * time.Second) return c.String(http.StatusOK, "ok") }) e.Logger.Fatal(e.Start(":8080")) }
Dockerfile을 추가해 이미지로 빌드해 컨테이너로 띄울 수 있도록 했다.
멀티스테이지 빌드를 활용해 이미지 사이즈를 최소화하려고 했다.
FROM golang:1.22 as builder WORKDIR /go/src/app COPY . . RUN go mod tidy && \ go mod vendor && \ CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build -a -o bin/app . FROM scratch WORKDIR /go/src/app COPY --from=builder /go/src/app/bin/app ./app ENTRYPOINT ["./app"]
Prometheus 설정
Prometheus 설정을 해준다.
우리는 8080 포트로 app을 띄워 서빙할 것이기에 해당 포트를 스크래핑하도록 설정했다.
뒤에서 docker-compose.yml 파일이 나올텐데, 거기서 우리 go-echo app의 앱이름을 “app”으로 지었기 때문에
app:8080 으로 타깃을 설정했다.global: scrape_interval: 15s # By default, scrape targets every 15 seconds. # Attach these labels to any time series or alerts when communicating with # external systems (federation, remote storage, Alertmanager). external_labels: monitor: "codelab-monitor" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: "appservice" # Override the global default and scrape targets from this job every 5 seconds. scrape_interval: 5s static_configs: - targets: ["app:8080"] labels: group: "app"
도커 컴포즈 구성
도커 컴포즈를 이용해 앱, Prometheus, Grafana를 함께 띄워 사용해본다.
version: '3.7' services: prometheus: image: prom/prometheus:v2.33.3 volumes: - ./etc/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml ports: - "9090:9090" command: - "--config.file=/etc/prometheus/prometheus.yml" - '--storage.tsdb.path=/prometheus' restart: unless-stopped grafana: image: grafana/grafana:8.4.3 environment: - GF_SECURITY_ADMIN_PASSWORD=1234 volumes: - grafana-storage:/var/lib/grafana depends_on: - prometheus ports: - '3000:3000' restart: unless-stopped app: build: . ports: - "8080:8080" volumes: grafana-storage:
실행
docker-compose로 컨테이너 띄우기
이제
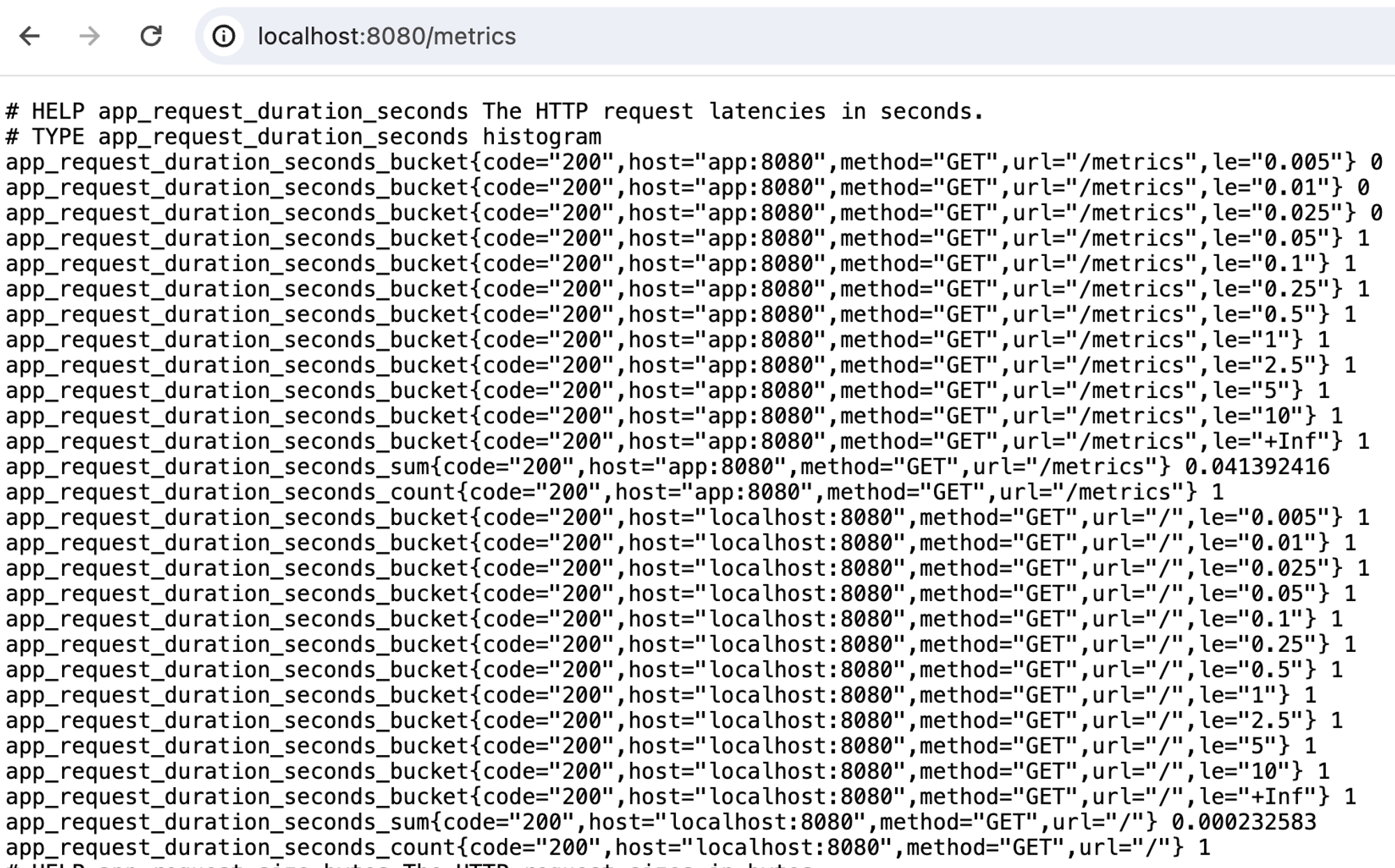
docker-compose up —build 로 서비스들을 시작해본다.localhost:8080/metric으로 접속하면 Prometheus가 주기적으로 수집해갈 metric을 한 눈에 확인할 수 있다.
localhost:9090에 접속하면 promethues 쿼리를 할 수 있는 웹 인터페이스를 확인할 수 있다.
- 마지막으로
localhost:3000에 접속하면 grafana를 확인할 수 있다.



Grafana에 data source로 Prometheus 추가

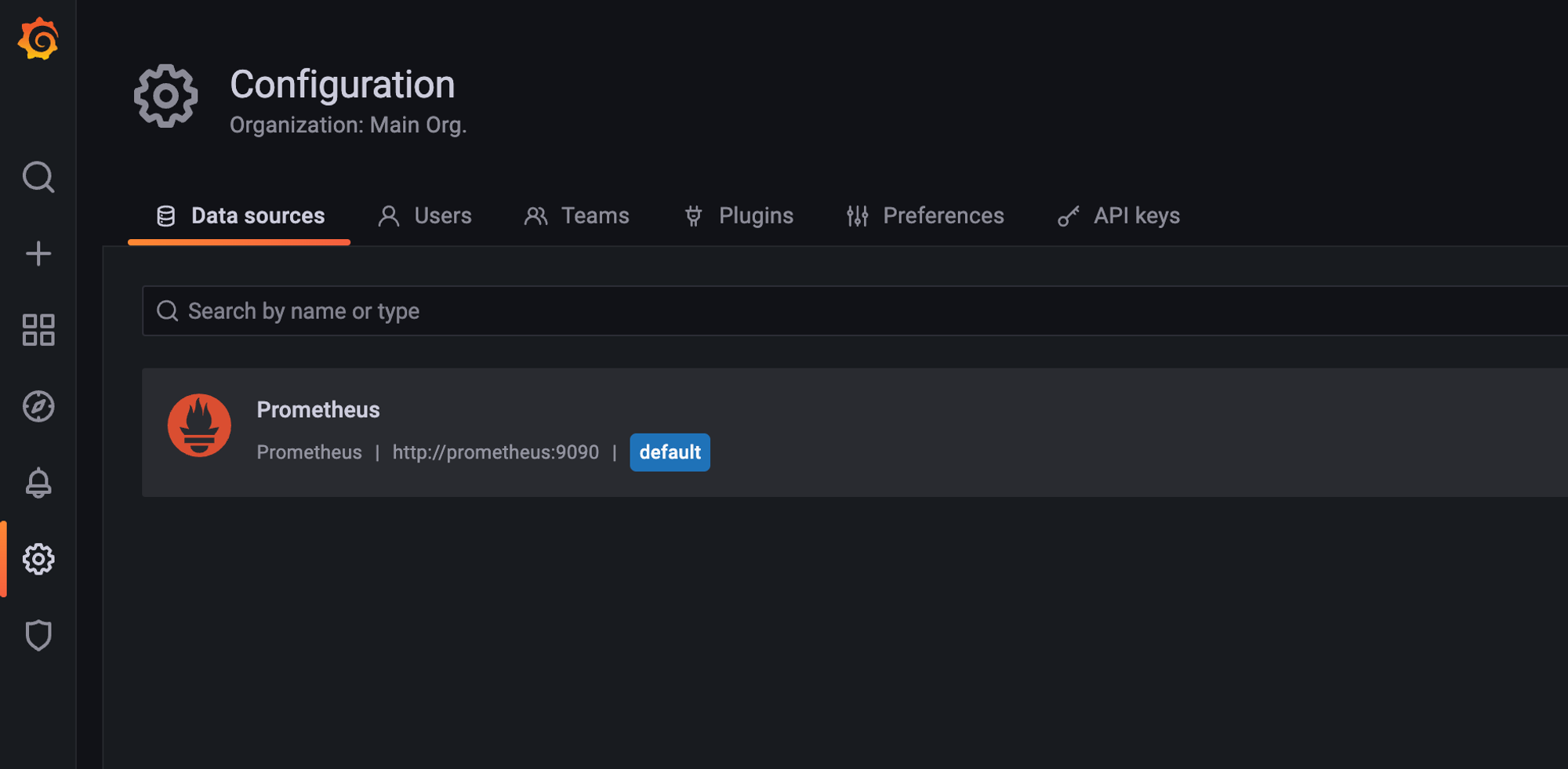
톱니바퀴 모양 아이콘을 클릭하면 “data sources”라는 메뉴가 있다. 해당 메뉴를 눌러 들어간다.
처음 실행했다면 위 사진과는 달리 추가된 데이터소스가 없을 것이다.
데이터 소스를 추가하자.
데이터 소스 추가 방법은 공식문서에도 잘 소개되어 있다.




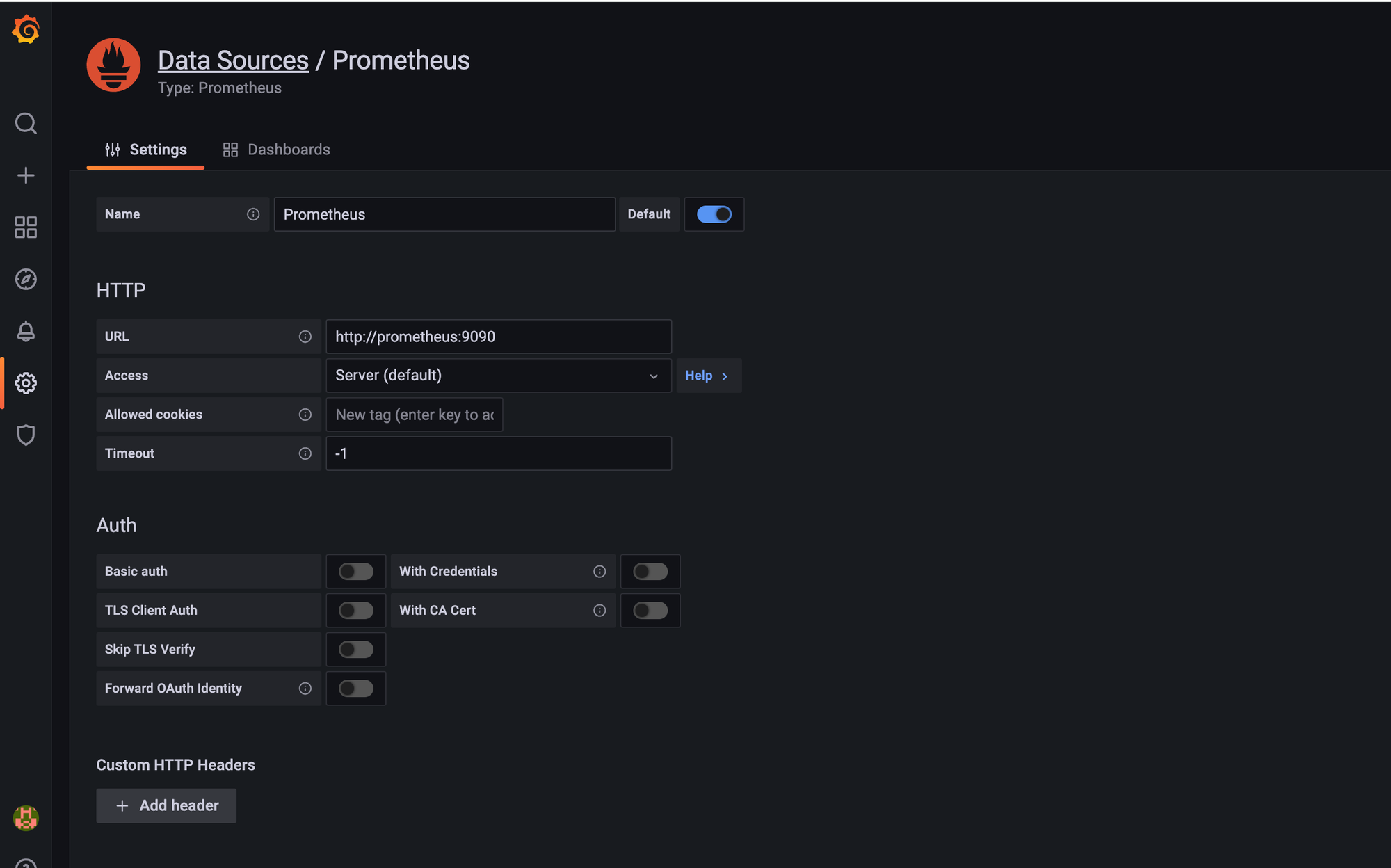
아래와 같은 설정으로 추가해주면 된다.
docker-compose에서 프로메테우스의 이름이 “prometheus”이므로 URL은
http://prometheus:9090 으로 해준다. 
Grafana에 p99 지연 모니터링을 위한 대시보드 추가
앞서 잠깐 설명했듯, 우리가 실행 중인 go-echo app은
/slow 라는 엔드포인트가 있는데, 요청시 1초 뒤에 200, ok가 반환되는 엔드포인트이다. 이 엔드포인트와 /엔드포인트를 번갈아 접근하면 p99 지연이 1초에 근접하게 된다.실제 서비스를 모니터링할 때도 p99 요청 지연을 종종 확인하므로 p99 확인을 위한 대시보드를 추가해 보자.
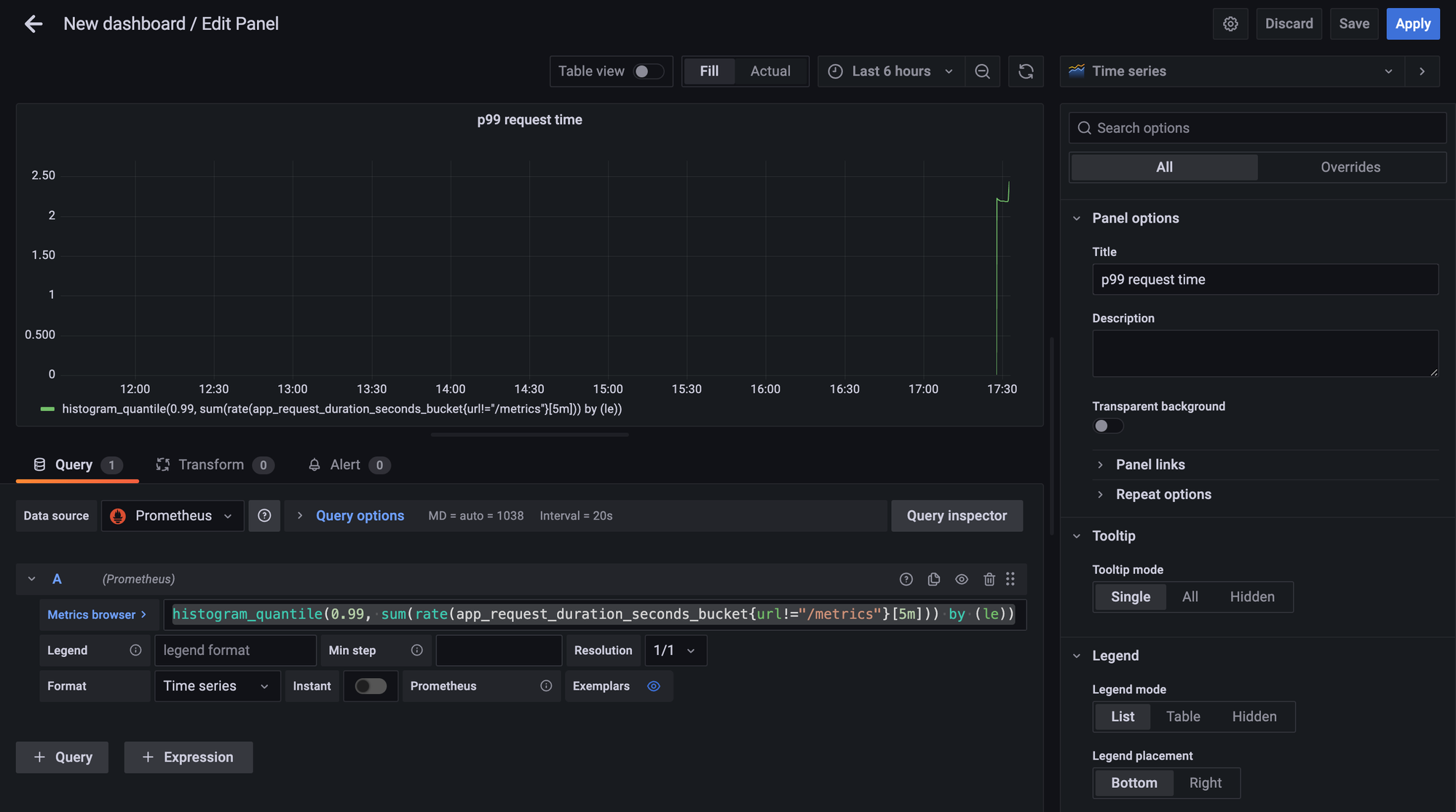
쿼리
histogram_quantile(0.99, sum(rate(app_request_duration_seconds_bucket{url!="/metrics"}[5m])) by (le))
histogram_quantile(0.99, ...)함수는 이러한 집계된 변화율을 사용하여 99번째 백분위수, 즉 99%의 요청이 완료된 지속 시간의 상한을 계산한다.
sum(...) by (le): 마지막으로,sum함수는 이러한 증가율을 집계하는데,le라벨 값별로 그룹화하여 집계한다.
rate(...[5m]):rate함수는 지난 5분 동안의 히스토그램 카운터의 초당 평균 증가율을 계산한다.
app_request_duration_seconds_bucket{url!="/metrics"}: 이는/metrics경로를 제외한 모든 URL에 대한 히스토그램 메트릭app_request_duration_seconds_bucket의 시계열 데이터를 선택한다.
/metric의 경우 주기적으로 스크래핑을 위해 접근하는 route이나, Prometheus에서만 사용하는 route이기 때문에 수집에서 제외했다. (우리가 날리는 request에 비해 Prometheus에서 훨씬 빈번하게 메트릭 수집을 위해 request를 날리기 때문에/metric이 포함될 경우 p99를 제대로 파악하기 힘들어서다)
만약 계산된 p99 값이 0.5초라면, 이는 최근 5분 동안 관찰된 요청 중 99%가 0.5초 이하의 지속 시간으로 처리되었음을 나타낸다. 즉, 가장 느린 1% 요청은 0.5초 이상 소요되었다는 의미이기도 하다.
Grafana에 추가
이제 이 쿼리를 아래 처럼 패널 추가 화면에서 추가해주면 된다.

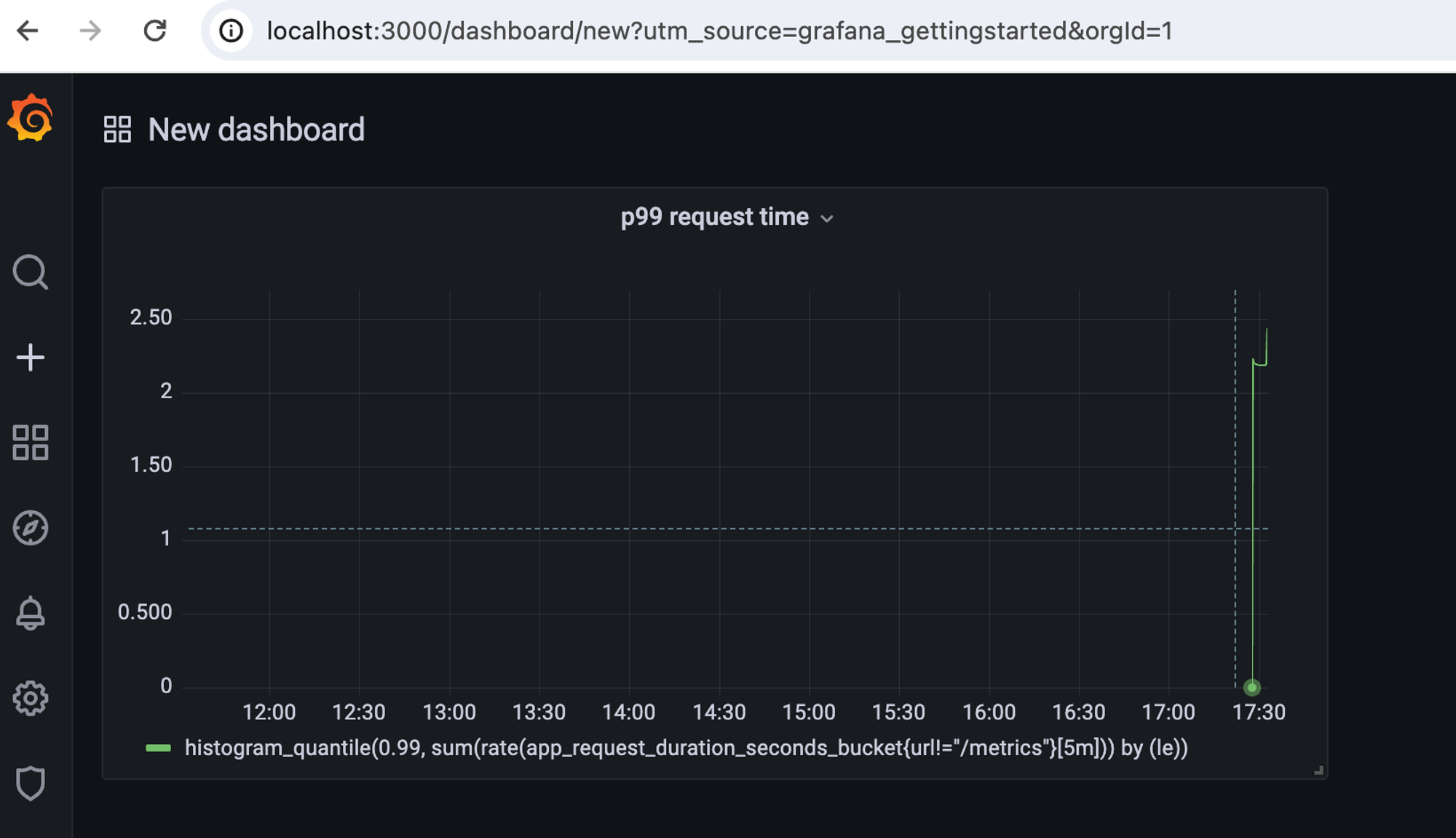
아래 사진은 추가가 왼료된 패널을 확인하는 화면이다.

마치며
아직 PromQL이 익숙하지 않아서 이것저것 시도해 봐야겠다. Grafana에 현재는 Prometheus만 연동된 상태인데 다른 data source들도 추가해봐도 좋을 것 같다.
또, Kubernetes에서 실제로 여러 컨테이너들을 띄운 후 모니터링 환경을 구축해보고 싶다는 생각도 들었다.
참고) 프로젝트 소스코드
monitoring
chaewonkong • Updated Mar 16, 2024